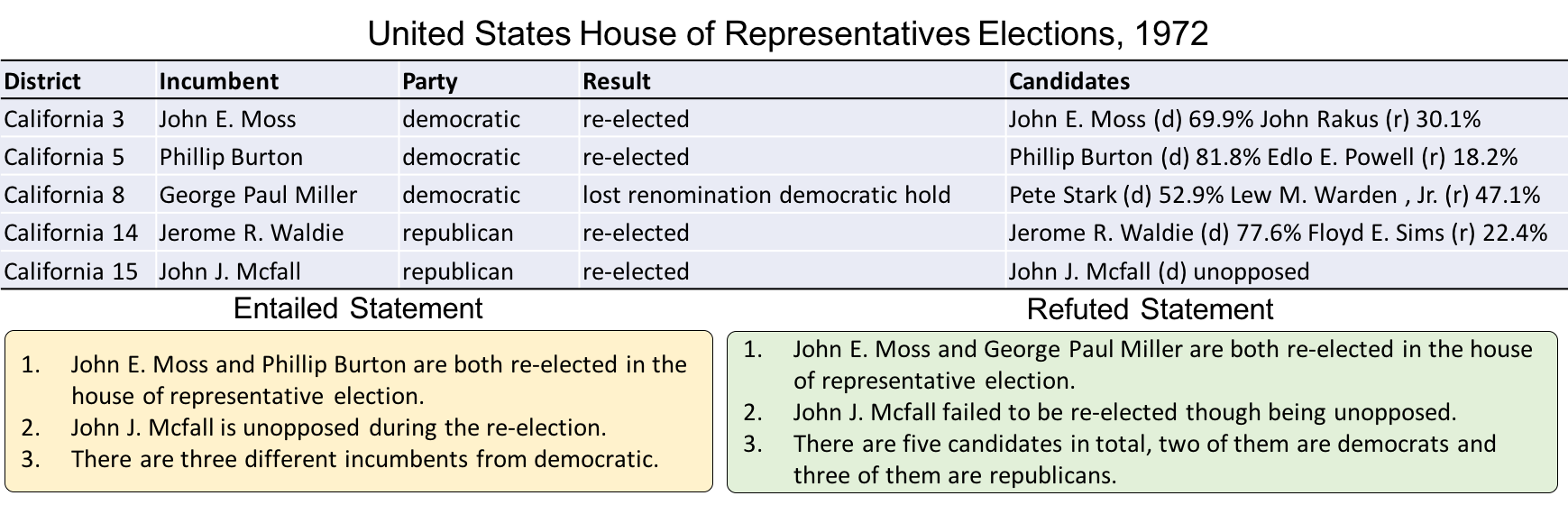
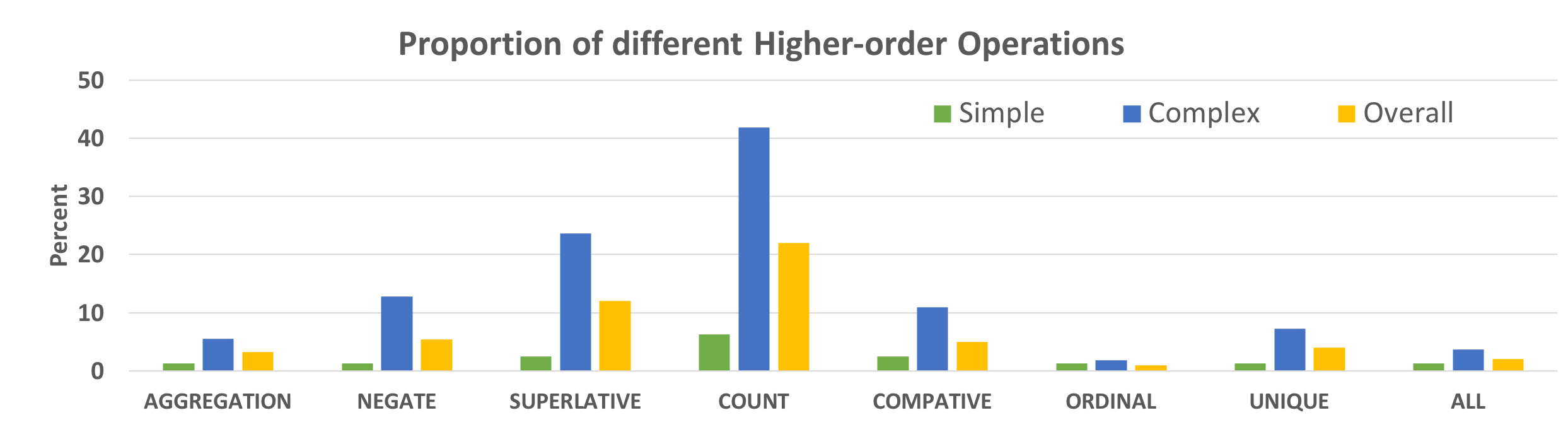
Why TABFACT?

HIGH-QUALITY
Mechanical Turk + Post filtering

LARGE-SCALE
16k Wikipedia tables as evidence for 118k human annotated statements for verification.

LOGIC-BASED
Natural language inference based on logic reasoning.

Open-Domain
Reasoning over open domain Wikitables